Goal: Convolutional Nural Network(CNN) 원리 한눈에 알아보기!
Reference :
A Comprehensive Guide to Convolutional Neural Networks — the ELI5 way
Artificial Intelligence has been witnessing a monumental growth in bridging the gap between the capabilities of humans and machines…
towardsdatascience.com
gif를 신봉해서 여기 있는 자료를 많이 쓸예정 대단하다. 백문이 불여일견... <저작권문제시 삭제>
Intro
Object detection관련하면 무조건 나오는 단어 CNN 드디어 감이 잡혔다. AI는 특히 Computer vision에 많이 쓰이는데 그럴만한 이유가있었다. machine learning을 공부하면서 이미지가 어떻게 데이터화가되고 판단이 되는지 궁금했는데 퍼즐이 맞춰졌다.
Main
우리가 해바라기를 보자마자 해바라기라 아는것은 아무힘도 들이지않고 판단할 수 있지만 컴퓨터 관점에서 보자면 굉장히 어려운일이다. 컴퓨터는 0,1 만 알기때문에 이를 수학적으로 풀어줘야한다. 고로 해바라기 이미지들은 작은 pixel(작은 네모들) 들이 모여서 우리가 보는 디스플레이 화면이될 수 있는데 이는 각 픽셀마다 수치가 들어가 컴퓨터가 이를 계산하여 과거 비슷한 값이 있는지 판단하여 해바라기라 결과를 알려줄 수 있는게 물체 인식의 뼈대이다.

CNN/ConvNet 은 컴퓨터가 이미지를 빠르게 계산하고 딥러닝을 이용할 수 있게 만들어주는 녀석이다.

Fig 1 이 지금 주제의 전부이다 어떻게 숫자 2를 쪼개고 쪼개서 마지막 초록색점들(neural network)에 학습시키는과정을 나타낸다. 좌측부터 대표적으로 1. convolution layer 2. max-pooling layer 3.Fully-connected(Neural Network) 로 구성되어있는데 차근차근 봐보자.
1. convolution layer

위그림을 보면 저 수만은 픽셀을 담은 이미지에서 convolved feature( convolution이란 단어는 중첩이란 뜻이있다) 쪽으로 데이터가 줄어들어가며 재생성되고있다. 이말은 즉슨 계산속도가 현저하게 좋아진다는것. 왜냐하면 한장의 이미지에는 수만~수백만의 픽셀들이 있을텐데 컴퓨터라고해도 이를 일일이 계산할려면 힘들다. 그러니까 주변에 있는 픽셀값들을 이용해 연관성을 담은 하나의 픽셀로 재생성하는것.
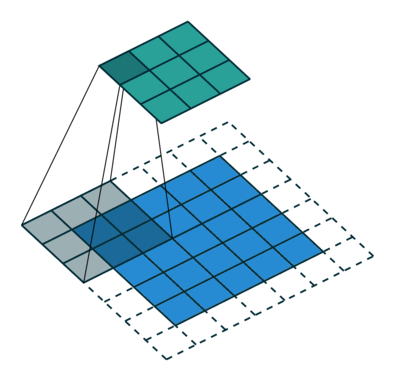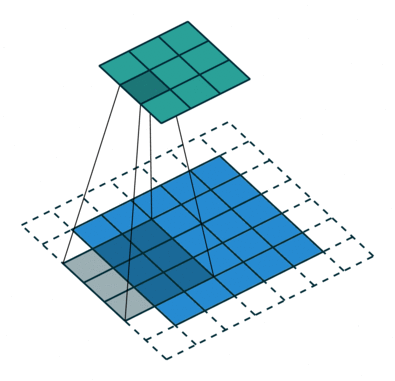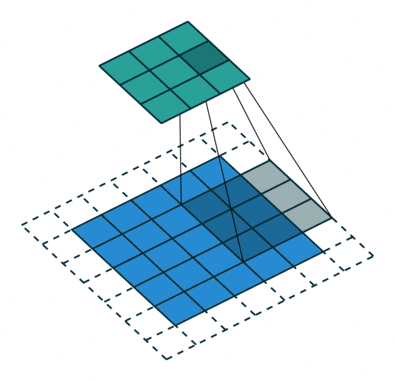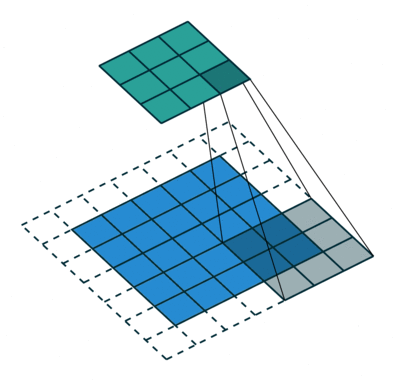
Fg2. 를 좀더 자세히 설명하자면 kernel filter 라는것 을 이용해 필요한 주변 픽셀들만 가져가며 *Stride Length (아래줄로 이동할때 점프하는칸) =1 인경우를 fg3. 에서 보여주고있다.
kernel/Filter, K =
1 0 1
0 1 0
1 0 1convolution의 목표는 이미지에서 구분점이 될만한 특징점(feature)(edge, color, gradient orientation)을 뽑아 다음 레이어에 넘겨줌으로써 computation(연산 시간)을 감소시키는것.!!! 픽셀 크기를 감소시키는것을 차원을 좀 줄인다고하는데 이는 padding 방법이 있는데 이는 fig .3에서 처럼 실제 픽셀 바깥에 가상의 공간을 만들어 주는것으로 사용할 수도 안사용할 수 도있다. 다양한 방법들이 존재한다!
2. pooling Layer

Pooling layer의 작업은 convolution layer의 작동방식과 비슷하다. computation을 줄인다 (계산할게 작아졌으니까) 그렇다면 다른점은 이 작업으로써 우세한 불변의 특징점(dominant feature)을 뽑아와서 좀더 강건한 데이터를 넘겨줄 수 있다. 그러니까 좀더 변하지않은 안정적인 데이터를 뽑을 수 있다. 필터같은거지.
pooling layer의 두가지 방법으로는 1) max pooling과 2) average pooling 이있는데 말그래로 최대값을뽑거나 평균값을 뽑아쓰는것이다. 아래 피규어에서 처럼 맥스 풀링은 4개의 그룹중 가장 높은 녀석을뽑고 어버레이지는 4개의 평균값을 쓴다. 허나 이 방법들은 환경 noise를 줄이는 역할을 충실하게 수행하여야하기 때문에 1)max pooling이 많이쓰인다고한다.

3. Fully Connected Layer (classificaiton)
이제 줄이고 줄이고 떠먹기 좋게 만든 이미지 값들을 fully connected layer에서 학습시키기 전 매트릭스로 되어있는 값을을 한번 펴줘야되는데 이 작업을 flattening이라고한다. neural network에서 먹기 좋은크기로 줘야하기떄문에 아래처럼 일자로 펴준다.

평탄화 작업을 끝내고온 nx1 vector는 feed-forward neural network 와 backpropagation에 적용이되어 softmax function을 통해 트레이닝이 되어 저장되어진다!.
conclusion:
CNN은 이미지 분류의 혁신적인 방식의 초기버전이고 이를 바탕으로 수많은 CNN버전이 나왔다. 이는 차근차근 알아보도록하겠다. 또한 YOLO 라는 이미지 인식 방식이 다른 branch로 나아가는데 이또한 비교해봐야한다.
NET (혹은 pipeline) 이라는 표현을 이미지 형상으로 생각해보면은 그물망으로 이루어진 수학 함수들이 이미지를 쪼개고 쪼개서 딥러닝(Nueral network)에 적용하기위해 사용되어지는 개념이라 이해하자.
'Robotics Engineer > Robot Perception' 카테고리의 다른 글
| [Ourdoor robot] Starship 배달로봇 위치 추정? (0) | 2024.04.21 |
|---|---|
| [Robot Perception] Object detection tutorial 따라하기(1) (1) | 2023.04.26 |
| [paper review]Current State of the Art in Object Detection for Autonomous Systems (1) | 2023.01.05 |
| [paper review] A Survey on Object Detection and Tracking Methods(2014) (0) | 2022.12.30 |
| [Vision] 1편: 모바일 로봇 비전 공부를 시작함에 앞서(overview) (1) | 2022.12.27 |




댓글