시험 준비와 딥러닝을 나름 빠르게 효율적으로 공부하기위해 고심한끝에 튜토리얼을 손수 먼저 풀고 이 중요도 기반으로 lecture slide를 빠르게 훓어 전체 시야를 확보한다.
Objectives
- Explain basic machine learning principles including
- Explain model capacity, overfitting and underfitting, hyperparameters
- Design and implement machine learning methods for linear regression and linear classification.
Tutorial

- Softmax function 유도식
- negative log-likelihood 유도식
Lecture slides

- 기본 구조 숙지
PART1: DATA

- 머신러닝의 핵심은 데이터로 부터 regression problem을 푸는것

- one hot coding은 클래스를 숫자화 시켜서 분류하게한것. 컴퓨터는 0,1밖에몰른다.
PART2: MODELS

- 모델을 표현하는 수식 인지하기
- THETA 는 linear모델에서 기울기인것으로 생각하기

- softmax model 은 튜토리얼에서 다뤘던만큼 중요. 역할은 output을 0 혹은 1로 변경해주며 각 클래스에 대한 예측 확률값을 계산시 사용하게 한다. 반올림역할 ex 0.3의확률가진 클래스라면 0 으로 바꿔버림.
- softmax가 왜필요해? classificaiton 문제에서 확률로 주어진 아웃풋값을 0 ,1로 바꿔 버림으로써 나중에 배울 back propagation(역전파) 개념에서 모델이 가중치(weight)완 편향(bias)을 계산하게할 수 있게하여 더 정확한 모델을 만드는데 도움을준다!

- 저기 아래 softmax함수가 쓰이며 각 클래스에대한 정답 확률이 나온것을 알수있다!

- 모델 capacity => 적당히 fit한 모델이 good.
PART3: LOSS FUNCTIONS

- Loss 값이 낮으면 낮을 수록 좋은것이 포인트.

- Maximum Likelihood Function(MLF)의 역할? 모델 파라미터를 예측하기위해! 어떤 파라미터가 좋은 모델을 만드는지 알아야할것아닌가 => 가장 좋은 모델을 만드는 파라미터 찾기
- likelihood function이 최대가되는 지점 = negative log-likelihood가 최저가 되는지점. (튜토리얼 개념)
- MLF 는 하나의 큰 방법론으로 그세부 테크닉으로 Gradient decent, Stochastic gradient descent가 있는것이다.

- 튜토리얼에 출제!!! 수학공식이 Q1에 나온다하심.
- 오른쪽 Loss function gradient 수식 다시써보기 -> 완료!
PART4: PARAMETER ESTIMATION

- 직관적으로 설명을 잘해주셨다. 기울기!
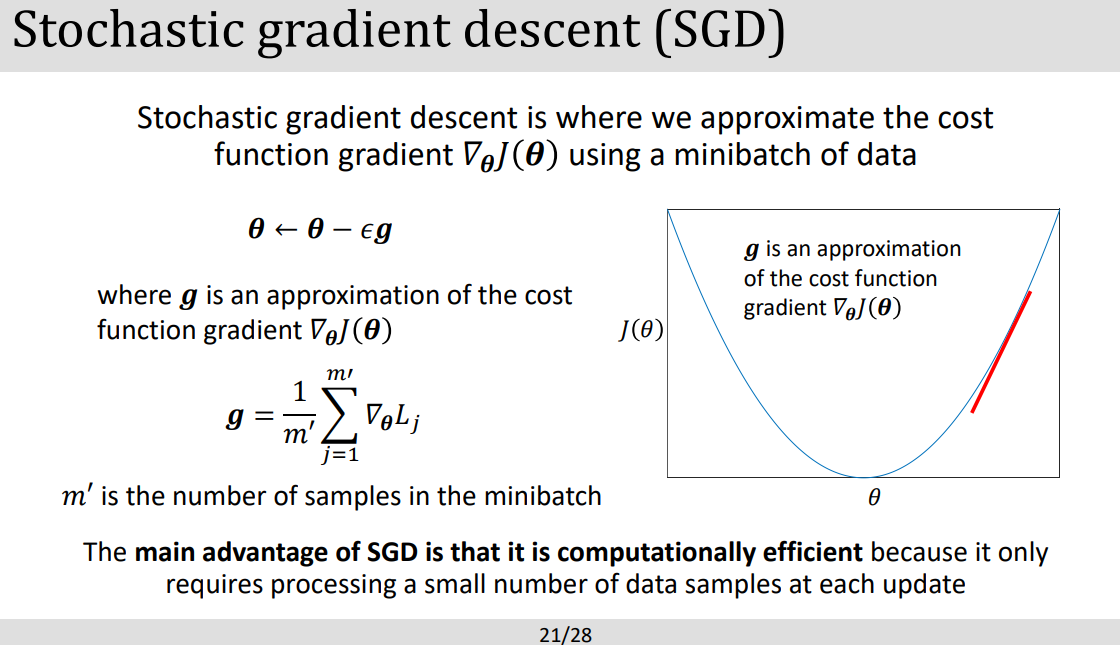
- [SGD VS GD] Optimization 방법론 중하나로 가장 많이쓰인다. SGD는 적은 BATCH를 랜덤하게 선택해서 모델 파라미터를 각 반복마다 빠르게 업데이트하여 큰 데이터에 강하다. 반면 GD는 전체 데이터를 먼저 이용해 Loss function의 기울기를 구해 상대적으로 많은 데이터에대해서 느리다.
- [단점] SGD는 Learning rate튜닝하기가 힘들고 그 이유로는 random sampling시 noise가 끼어있어서 ocilliation이 일어나기 때문.
- 여기서말하는 mini batch는 tranining data의 작은 집합같은걸로 전체데이터중에 몇개씩 뭉쳐서 트레이닝을 시킬 건지 결정하는 개념이다.
- [추가 개념]
- batch 가 크다 => overfitting 올라감, 빠르게 수렴함 ////
- batch 가 작다 => 노이지한 기울기 발생한다, 적은 데이터에 트레닝 할수있다.
'[End]Robotics Lectures in UoS > Deep Learning' 카테고리의 다른 글
| [DL] Lecture6:Deep learning for computer vision (0) | 2023.05.06 |
|---|---|
| [DL] Lecture5: Convolutional Networks (0) | 2023.05.05 |
| [DL] lecture4: Optimization and Regularization Techniques (0) | 2023.05.05 |
| [DL] Lecture3: Deep Feedforward Networks-시험공부 (0) | 2023.05.05 |
| [Deep Learning] 코스 시작! (0) | 2023.02.10 |




댓글