Objectives
- Explain methods for natural language processing including text representation and word embeddings, attention models, Transformer networks and automated speech recognition
- Design and implement deep learning methods for natural language processing
Tutorial

- a simple encoder-decoder recurrent network
- The attention model in the transformer
7과의 RNN개념에 이어서~
PART1: TEXT REPRESENTATION

.


PART2: ATTENTION

- Attention mechanishm은 transformer에서 굉장히 중요한 역을 하는데 이는 각각의 연속적인 인풋 들에서 각각의 요소들의 attention weight을 계산하여 무엇이 중요한지 파라미터를 업데이트한다.
- Attention model은 3가지 중요 요소로 이루어져있는데 query, key, value vectors들로 이루어져있다. query vector는 디코더 안에있는 현재의 위치를 표현하고 key,value vector들은 엔코더안에서의 위치나 디코더에서 그 이전 위치를 가르킨다.
- attention 모델은 비슷한 점수(similarity score)를 query vector 와 key vector사이에서 dot product로계산하게 되는데 이 (similarity score)는 attention weight으로 softmax를 통해 전달된다.
=> attention mechanism은 연속적인 값들의 연관성을 찾아내기위한 방법이라고 볼수있다.

- 튜토리얼 출제.
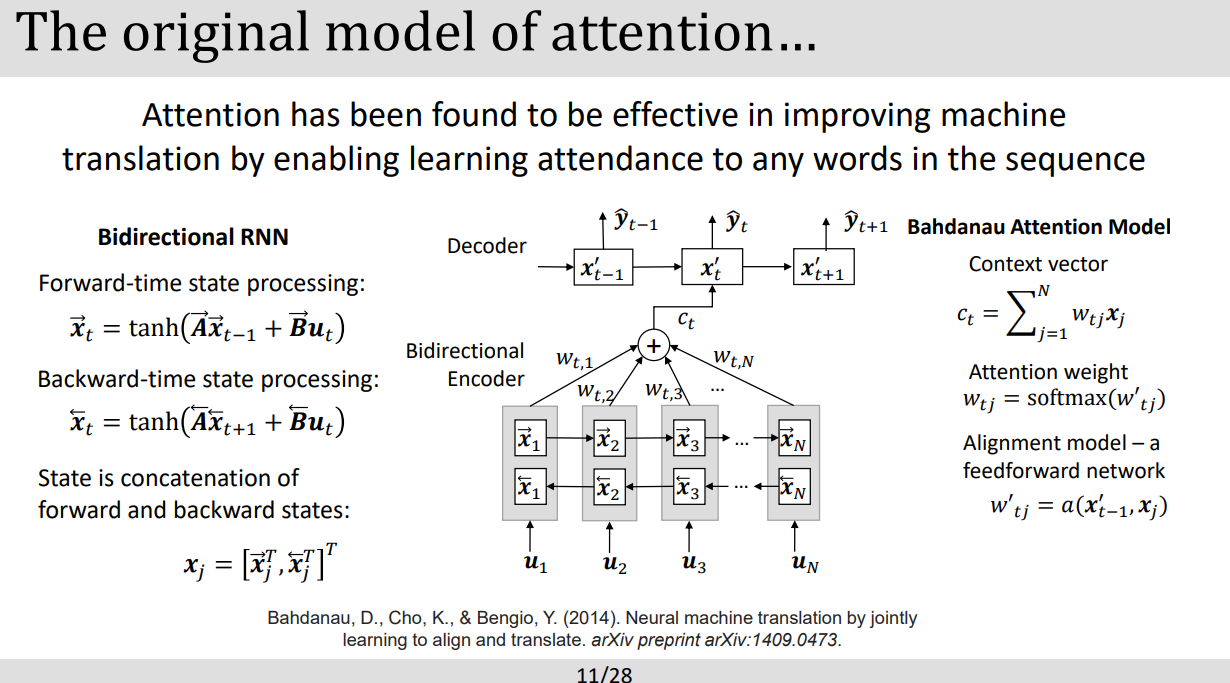

- 이는 past paper로 어떤 유형이 나오는지 확인해보자
PART3: THE TRANSFORMER
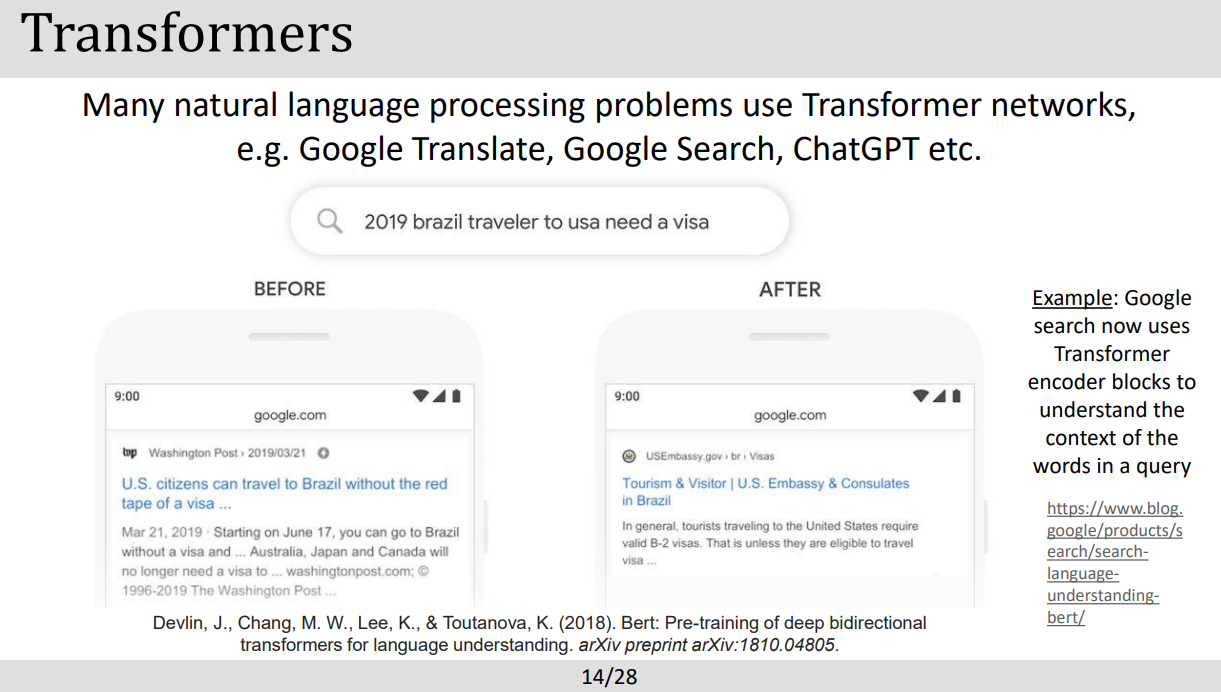

- RNN은 Feedforward를 사용하지않고 memory 방식으로 sequential data에대해 좋은 결과를 가져왔었지만 방대한 양을 다뤄야하는 gpu 연산에는 적합하지않았다. 그래서 발현된것이 transformer model. (우리 데이터는 짱많은데 이걸 어떻게 효율적으로 이용할 수 있을까?에서 발생된듯)
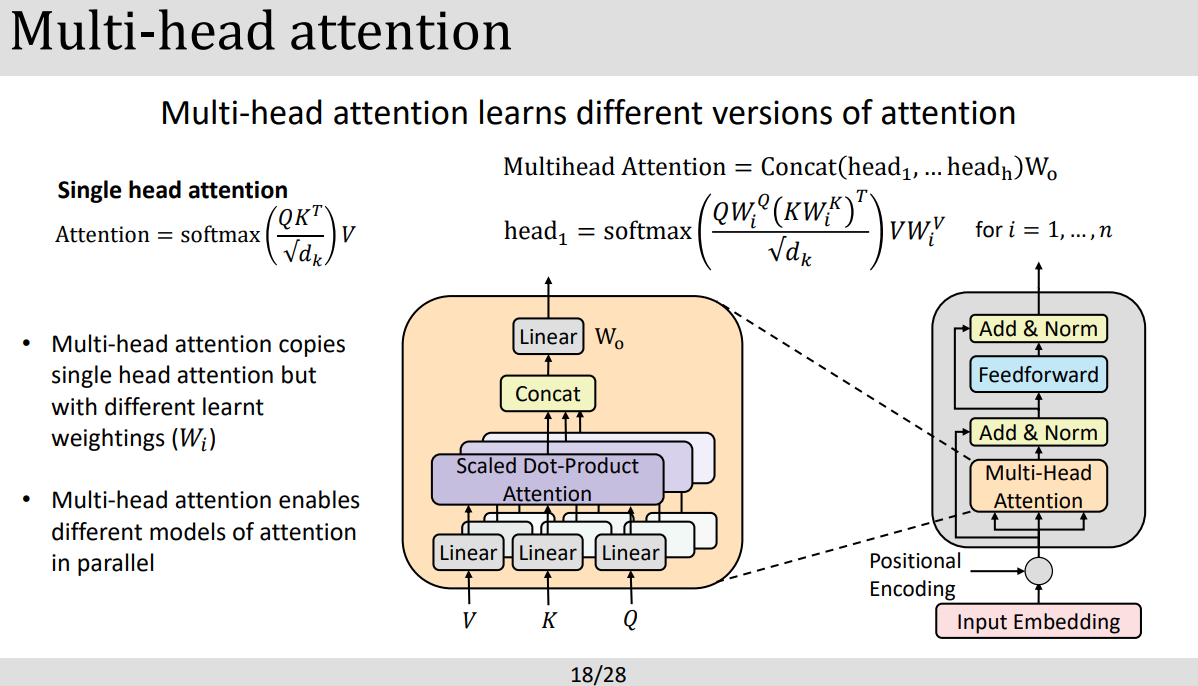
- Transformer model은 2017년에 처음 발표되었고 현대 GPU에 맞게 병렬연산에 최적화된 모델이다. 기본 구성은 Recurrent layer를 self-attention layer 바꾸었다. 큰 구조로는 encoder와 decoder로 이루어져있는데 각각의 코더는 sub-layer들을 가지고 있고 그 레이어들은 multi-head sefl -attention mechanism과 position-wise fully connected feedforward network. layer normarlization이 적용되어 각 하위계층들의 트레이닝을 안정화 시킨다.




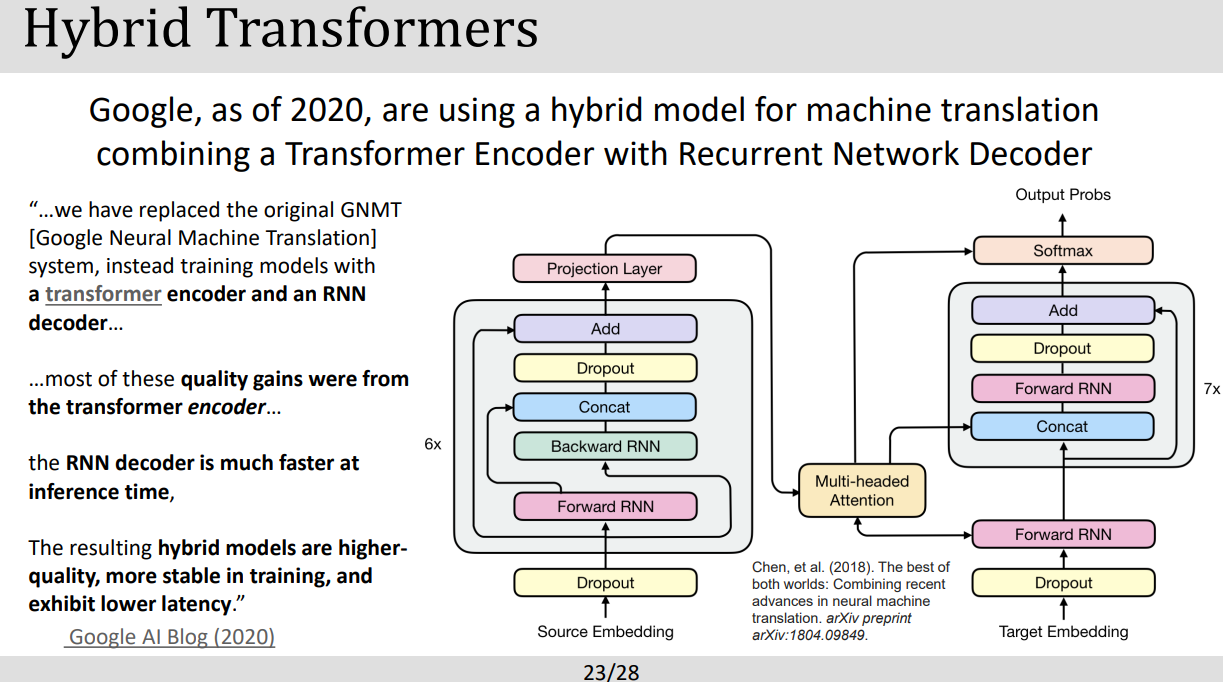
PART4: AUTOMATED SPEECH RECOGNITION

'[End]Robotics Lectures in UoS > Deep Learning' 카테고리의 다른 글
| [DL] Lecture 12: RL using Tabular methods (0) | 2023.05.25 |
|---|---|
| [DL] Lecture11: Intro to Reinforment Learning (0) | 2023.05.24 |
| [DL] Lecture7: Recurrent Networks (0) | 2023.05.06 |
| [DL] Lecture6:Deep learning for computer vision (0) | 2023.05.06 |
| [DL] Lecture5: Convolutional Networks (0) | 2023.05.05 |




댓글