집중이 안되는 관건으로 비버 딥러닝 교수님(지도교수) 얼굴 붙이고 공부해야겠다. 힘을 주세요. 오늘안에 끝내기


- Tabular methods는 강화학습에서 Q-Table을 사용해 각 state-action pair를 discrite하게 테이블에 저장하는 방법이다.
- Q-learning은 보통 tabular method를 사용한다고보면된다.
- tabular method 장점:
- 1. 해석가능하게 투명한 과정을 보여준다. 이는 black box형태의 딥러닝형태가아닌 어느 Q -value를 사용하여 결과가 나왔는지 해석가능한점이있다.
- 2. computation이 효율적으로 이루어지며 small domain 영역에서 빠른속도로 수렴을 가능하게한다.
- 단점?:
- 1. tabular method는 작고 , discrete한 문제에 국한되는 문제가 있는데 이는 exponential growth 하는 Q -table의 성질에 의해서 그렇다. 그렇기게 크거나 continous 한문제에는 deep Q-network가 도입도니다.
PART1 INTRO


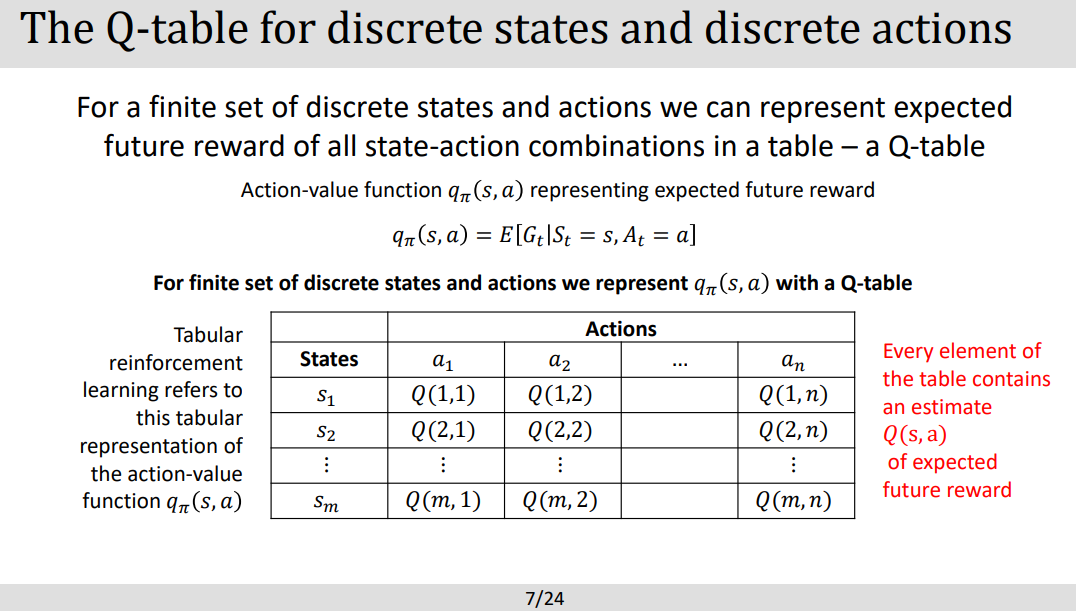
- 위에서 서술한것처럼 STATE 와 ACTION 테이블로 짝이 이루어져있다.
- STATE- ACTION 의 미래 보상값을 예측할 수 있다.


PART2 SARSA (on-policy)

- SARSA (State- Action- Reward- State -Action) 는 all in one package 로 생각하면 쉽다. model-free method를 사용하여 optimal policy를 바로 학습하며 환경모델이 필요하지않다. SARSA는 state -acition인 Q value를 관측된 reward와 state-action pair로 예측하며 agent가 학습을 진행한다. => 사건으로 학습진행, 어려운 모델 몰라~



- 여기서 bootstrapping이란 비유는 자기 손으로 직접 처리하는 의미여서 SARSA가 외부의 도움을 받지않고 model Estimate를 한다는 뜻에서 사용.
PART2 : Q-LEARNING (off-policy)





- On-policy vs Off-policy : on-policy는 current policy's data에 의해 학습, off-policy는 다른 policy에 의해 생성된 데이터로 학습하는 차이
- On-policy learning : Agent는 자기가 직접 경험한것을 현재 policy에 맞춰서 학습한다
- 장점:
- 안정적인 수렴; agent는 같은 policy들에 의해 학습되기때문에 ,
- 복잡한 환경에 효율적; 직접적으로 노이즈를 current policy에 적용할수있어서
- 단점:
- 데이타 비효율; agent들은 새로운 데이터를 생성할때 environment들과 policy들이 interation한것이 필요하기때문에 (왜 그게 비효율인데?
- exploration-exploitation trade-off; 밸런스 있는 새로운 액션 탐색과 최적화선택이 이루어지지 않을수있다.
- 장점:
- Off-policy learning: 위에서 설명한것처럼 agent가 학습할때 다른 policy에서 수집된 데이터로 학습한다.
- 장단점은 on-policy와 반대!!ㅈ
PART 4 DEMO




'[End]Robotics Lectures in UoS > Deep Learning' 카테고리의 다른 글
| [DL] Lecture 14: Policy Gradient and Actor-critics (0) | 2023.05.26 |
|---|---|
| [DL] Lecture 13: Deep Q-learning (0) | 2023.05.25 |
| [DL] Lecture11: Intro to Reinforment Learning (0) | 2023.05.24 |
| [DL] Lecture8: Natural Language Processing (0) | 2023.05.07 |
| [DL] Lecture7: Recurrent Networks (0) | 2023.05.06 |




댓글