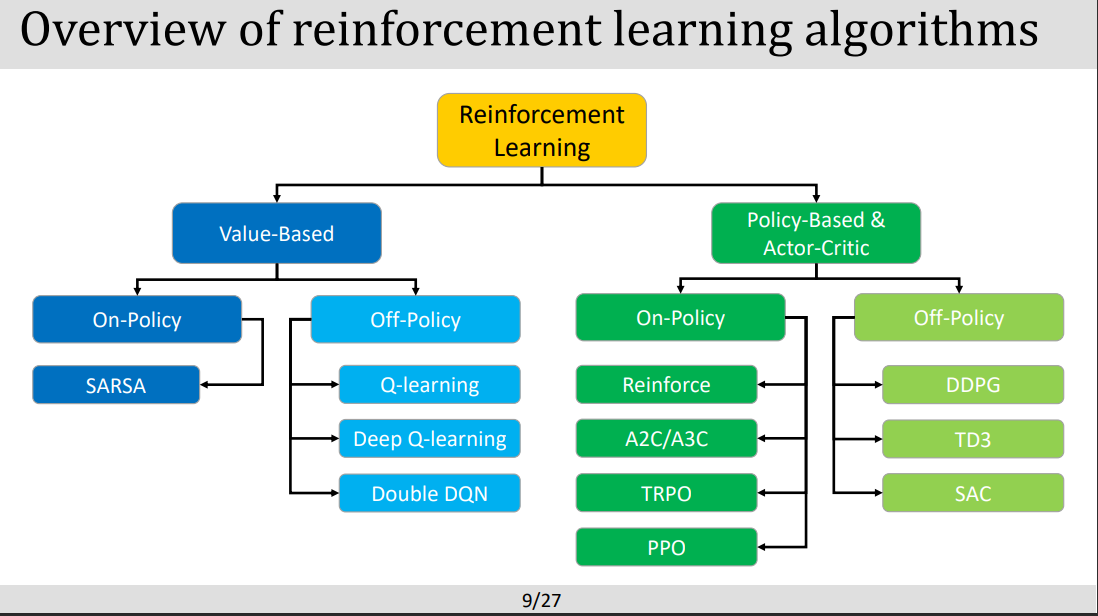
강화학습 마지막 렉쳐. 자 그 이전까지 valie-based로 On-policy와 off-policy를 다루었다면 이제 policy-based와 action-critic를 알아볼차례.
1. Policy Gradient Methods:
목표: 매개 변수와 관련하여 Policy 성능의 기울기를 추정하여 Policy을 직접 최적화하는 것.이러한 방법은 값 함수를 추정하는 대신 기대되는 누적 보상을 최대화하는 정책을 직접 검색함.
대표적인 알고리즘 : Proximal Policy Optimization (PPO), and Trust Region Policy Optimization (TRPO).3
2. Actor-Critic Method
actor-critic 방법은 actor(행위자)과 critic 함수(비판적)를 모두 결합. actor는 현재의 policy에 근거하여 행동을 만들어 내고, critic는 특정 상태에 있거나 특정 행동을 취하는 것에 대한 가치나 기대되는 누적 reward을 평가.
actor-Critic 방법에서 critic는 가치 함수를 추정하여 actor에게 피드백을 제공. 값 함수는 quality of action 을 평가하고 policy 업데이트를 안내하는 데 사용함.. critic의 estimation은 policy의 성능에 대한 보다 안정적인 측정을 제공하기 때문에 학습의 분산을 줄인다.
장점: actor-critic 방법은 policy based method 과 value-based 방법의 이점을 모두 활용. 그들은 policy 업데이트의 분산을 줄이는 데 도움이 되는 value function의 지침을 활용하여 pure gradient method 방법보다 더 효율적으로 학습할 수 있다.
대표적알고리즘 : Advantage Actor-Critic (A2C), Asynchronous Advantage Actor-Critic (A3C), and Deep Deterministic Policy Gradient (DDPG).

PART1: INTRO

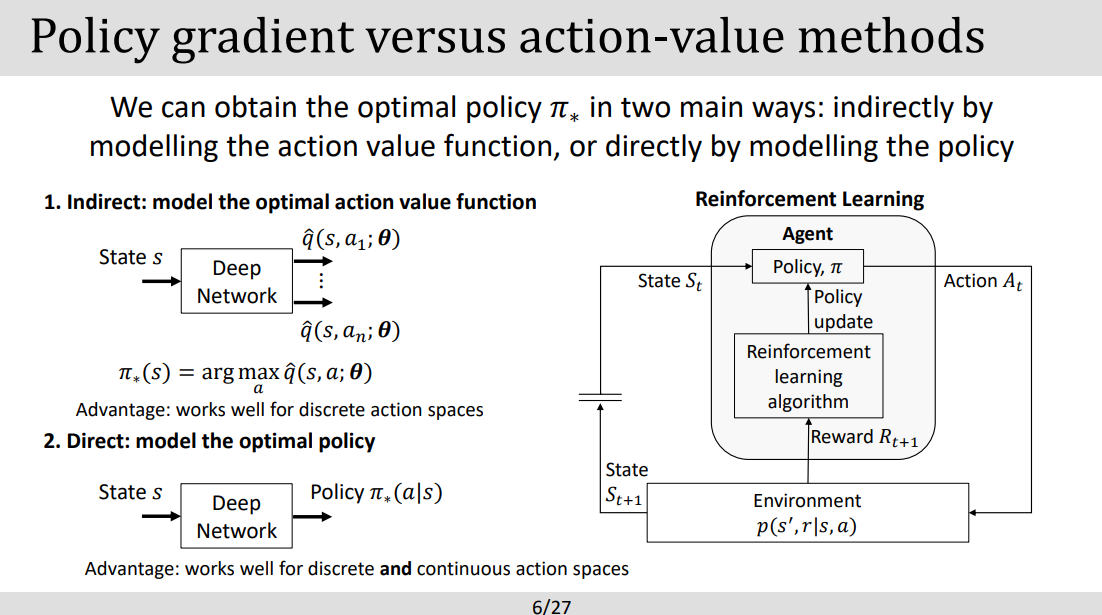


- 구조 살펴보기 .
PART2: Deep deterministic policy gradient TD3 (Off-policy actor-critic method)






PART3: Proximal policy optimization (on-policy actor-critic method)
Proximal policy optimization PPO는 업데이트를 "Proximal 근접" 영역으로 제한하면서 policy을 반복적으로 업데이트하는 policy 최적화 알고리즘. 그것은 클리핑된 surrogate(대리) 목표를 사용하고 강화 학습 작업에서 안정성과 향상된 샘플 효율성을 달성하기 위해 여러 시기의 최적화를 수행합니다.








'[End]Robotics Lectures in UoS > Deep Learning' 카테고리의 다른 글
| [DL] Lecture 13: Deep Q-learning (0) | 2023.05.25 |
|---|---|
| [DL] Lecture 12: RL using Tabular methods (0) | 2023.05.25 |
| [DL] Lecture11: Intro to Reinforment Learning (0) | 2023.05.24 |
| [DL] Lecture8: Natural Language Processing (0) | 2023.05.07 |
| [DL] Lecture7: Recurrent Networks (0) | 2023.05.06 |




댓글